The Problem With Correcting for Multiple Comparisons
The Problem With Correcting for Multiple Comparisons
It has been widely considered within the scientific community that the threshold for statistical significance of a value depends on the amount of comparisons being calculated in a dataset. The most popular way to correct for multiple comparisons is the Bonferroni correction, in which the threshold for statistical significance of each comparison is divided by the amount of comparisons being (e.g., the common threshold for statistical significance is p=0.05, but if making 5 comparisons, each value would have to be significant at p=0.01 or less for it to be considered significant at the original threshold). However, correcting for multiple comparisons is problematic, which I will demonstrate.
Imagine a study were conducted that calculated the correlation between two 1000 item scales, in a sample size of 100, where the correlation was computed to be 0.35. The p value would far surpass the threshold for statistical significance, at a p value of 0.000358, meaning there is a 99.96% probability of finding similar values in a similar population. Say this result is published, but after the original correlation was published, a second paper was published that reported correlations between the 2000 items of the scales. Now, the amount of comparisons made with the dataset is 1,999,001, and the statistical significance of the original value must pass the 0.05 threshold divided by 1,999,001 for it to be considered likely for similar values to be found in another similar population. Now, the likelihood of finding a similar value of 0.35 in a similar population has dropped from 99% to 0.007%, but if the second set of correlations were never calculated, the likelihood would still be 99%. Making 1,999,001 comparisons increases the likelihood that false positives would be found from the dataset, however for each individual comparison it cannot exactly be said that the probability of that value being found in a similar population is now lower. The amount of variables that can be compared is essentially infinite (e.g., if you also added two of each items, and then calculated the correlations between all of the added items, then divided each item by each other item and calculated the correlations between the divided items, etc..) meaning that any correlation could be brought down to a 0% probability of being replicated if enough comparisons were to be calculated.
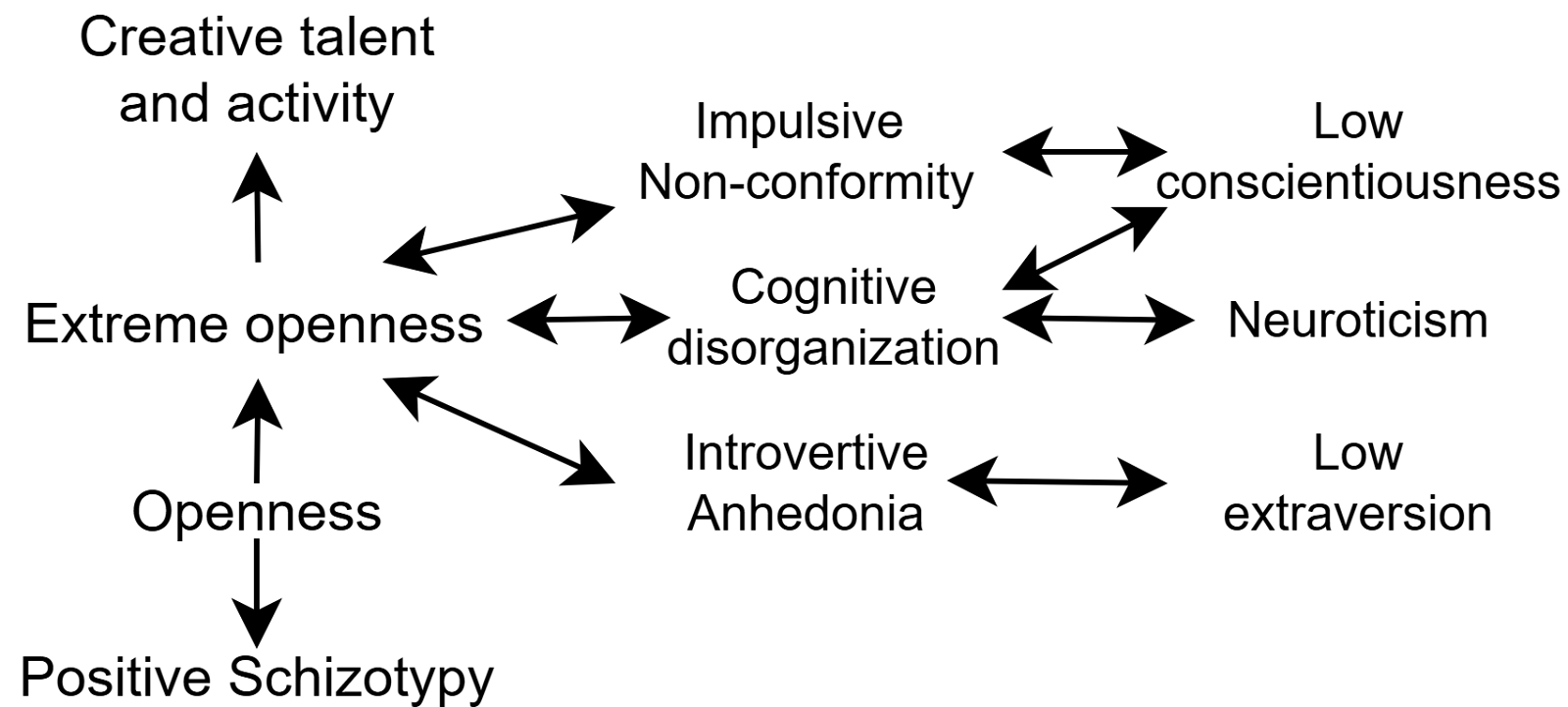
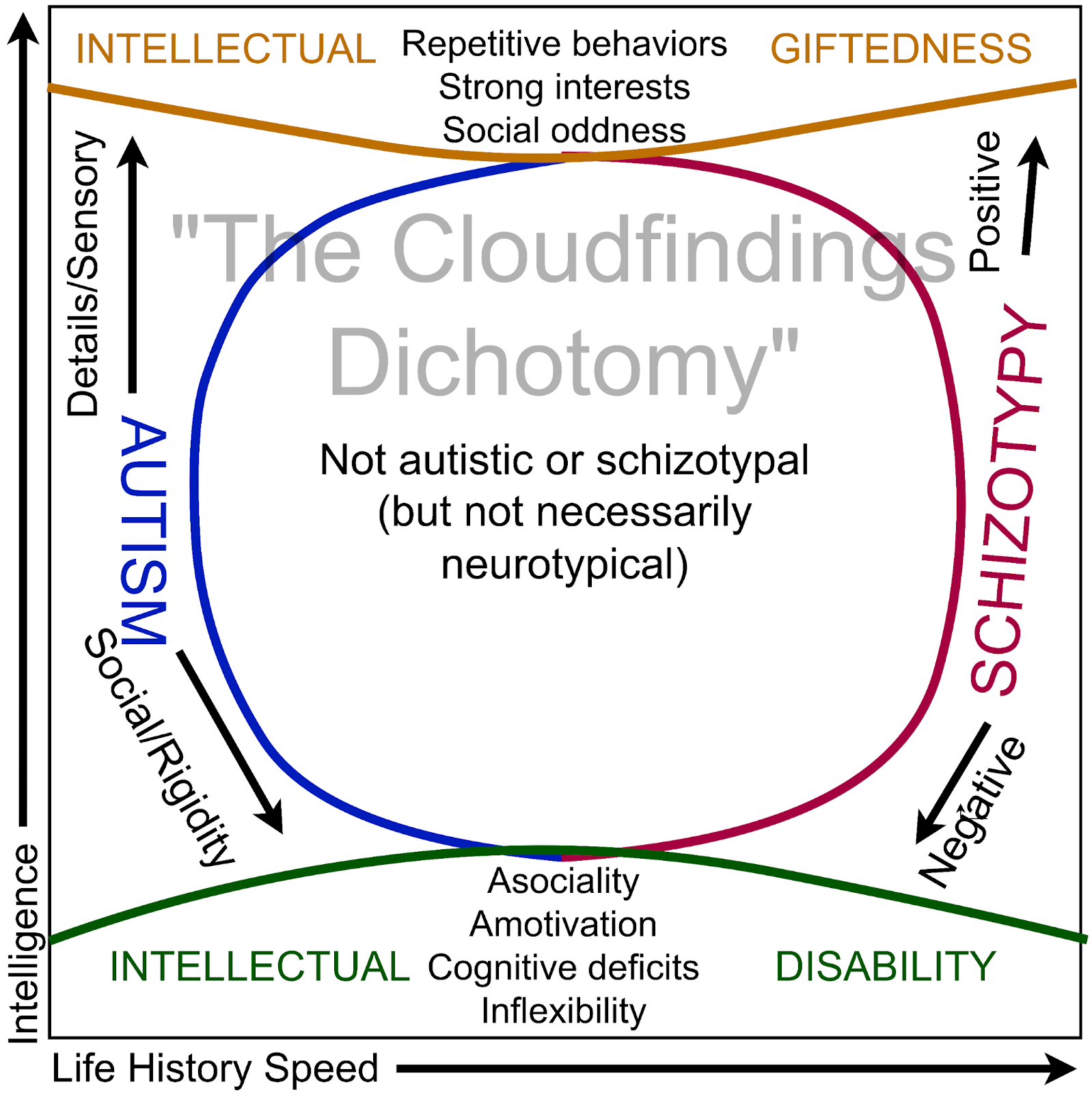
Comments
Post a Comment